
Table of Contents
- What STT actually does in a voice agent
- The three options — what each actually is
- Head-to-head benchmarks — 12 dimensions
- Case study: Voice AI startup migrates Whisper → Deepgram
- ROI Math — 3 STT Scenarios
- Common objections — honest answers
- What SuperMIA uses — and why
- Frequently Asked Questions
- The bottom line
TL;DR
- Deepgram Nova-3 + Flux wins for real-time phone agents where sub-300ms streaming latency and native turn detection matter most. $0.0077/min streaming.
- AssemblyAI Universal-3 Pro wins for accuracy-critical deployments — lowest benchmark WER and 30% fewer hallucinations than Whisper. $0.45/hr streaming.
- Whisper Large V3 Turbo wins for budget-constrained, on-prem, or multi-language deployments where you have ML engineering capacity.
- Most production voice agent teams land on a hybrid: Deepgram for streaming primary, Whisper self-hosted for fallback or batch analysis.
- Benchmark on YOUR audio, not the marketing recordings. WER on clean audio tells you almost nothing about WER on your actual phone calls.
Your voice agent's accuracy ceiling is set by your speech-to-text layer.
Get the Deepgram vs Whisper vs AssemblyAI decision wrong on day one, and you'll be migrating providers six months later — usually after a customer complaint reaches the CTO.
This isn't a generic transcription comparison. It's a production-engineering breakdown of how Deepgram Nova-3, AssemblyAI Universal-3 Pro, and OpenAI Whisper Large V3 Turbo perform inside a phone-based AI voice agent — where 8kHz PSTN audio, sub-800ms latency budgets, and hallucination-triggered tool calls all matter more than benchmark WER on clean studio recordings.
"We picked Whisper because it was free. Six months and $140K in engineering time later, we switched to Deepgram. The real lesson: 'free' means 'you're paying with engineering hours instead of API fees.' Benchmark at YOUR scale before deciding. Don't trust vendor WER numbers."
What STT Actually Does in a Voice Agent
Speech-to-text (STT) is the first AI layer in a voice agent pipeline. It converts the caller's spoken words into text the LLM can reason over. Accuracy here caps every downstream capability: if STT misreads 'cancel' as 'confirm,' your voice agent will cheerfully commit to the wrong action. Streaming STT delivers partial results every 100–200ms so the agent can respond before the caller finishes speaking.
Key Takeaways
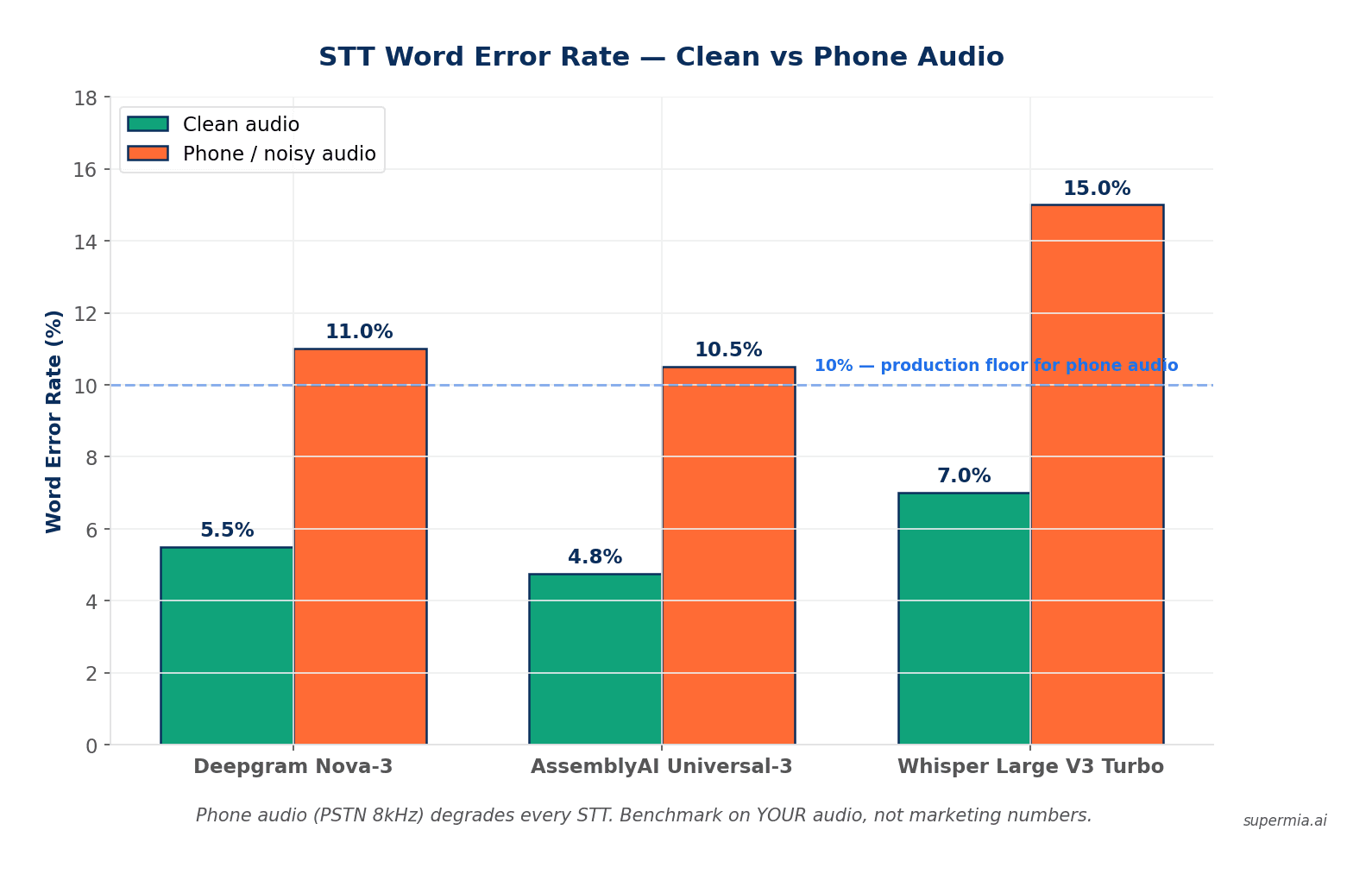
- ✓ STT accuracy on real phone audio runs 10–18% WER — double the 5% benchmark numbers in vendor marketing.
- ✓ Hallucination rate matters for function-calling agents. AssemblyAI's 30% reduction vs Whisper is meaningful.
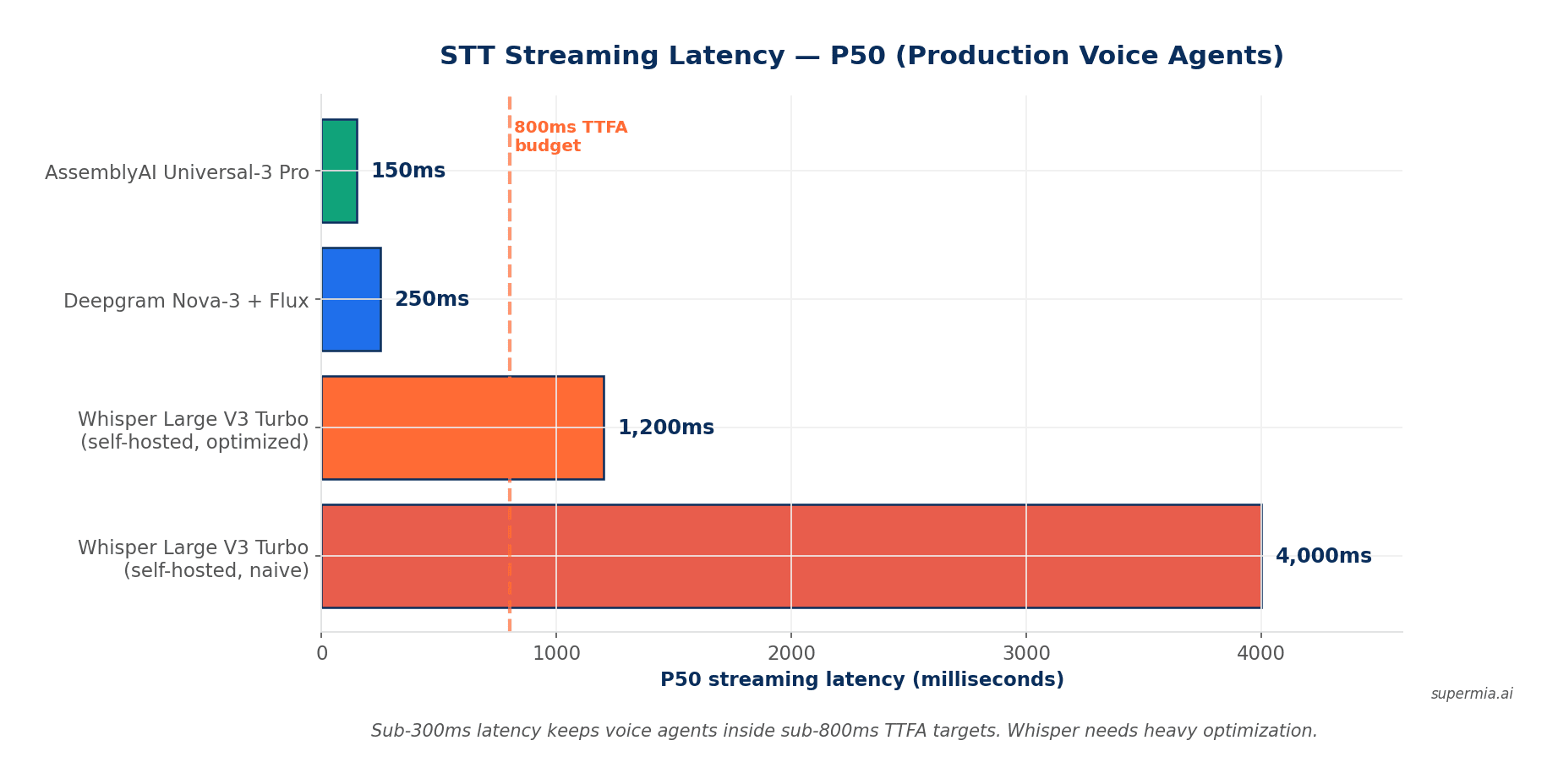
- ✓ Deepgram's Flux includes native end-of-turn detection — removes a VAD layer, cuts 50–80ms latency.
- ✓ Whisper is 'free' only if you already pay for GPU infrastructure. Fully loaded cost at 100K min/mo is $400–1,200/mo.
- ✓ Switch cost between STT providers is lower than most teams assume: 1–2 weeks if your pipeline is abstracted cleanly.
The Three Options — What Each Actually Is
Deepgram Nova-3 + Flux
Deepgram is a speech-AI-first company with purpose-built models for voice agents. Nova-3 is their general-purpose transcription model; Flux extends it with native end-of-turn detection, configurable turn-taking, and ultra-low latency optimized for voice agent pipelines. Nova-3 Medical is fine-tuned on medical vocabulary including pharmaceutical names, clinical acronyms, and Latin-derived disease terminology.
Deepgram prices streaming at $0.0077 per minute on the pay-as-you-go tier, and batch at $0.0043 per minute. Real-time streaming latency runs sub-300ms with Flux. Customers include Spotify, NASA, Citibank, and LaunchDarkly. SOC 2 Type 2, HIPAA BAA, and on-prem deployment for enterprise plans.
AssemblyAI Universal-3 Pro
AssemblyAI is positioned as the most accurate cloud STT. Universal-2 delivered approximately 8.4% WER across diverse datasets with 30% fewer hallucinations than Whisper Large-v3. Universal-3 Pro Streaming adds ~150ms P50 latency and a 16.7% missed entity rate — lowest among major providers. The platform bundles audio intelligence features (sentiment, PII detection, content moderation, topic detection) into the same API call.
Streaming costs $0.45/hr on pay-as-you-go. SOC 2 Type 2, HIPAA BAA support.
OpenAI Whisper Large V3 Turbo
Whisper is OpenAI's open-source STT family. Whisper Large V3 Turbo (October 2024) delivers 5.4x speed improvements while maintaining accuracy close to Large V3. Supports 99+ languages pretrained. The catch: latency in many self-hosted implementations runs 1–5 seconds, which fails sub-800ms TTFA requirements for phone agents. Getting Whisper to production voice-agent latency requires significant engineering work.
Whisper is free at the model level, but you pay for GPU infrastructure. At 100,000 minutes monthly, expect $400–1,200/mo in compute. OpenAI's managed Realtime API combines Whisper with GPT-4 at $0.06/minute — significantly more expensive than Deepgram or AssemblyAI.
Head-to-Head Benchmarks — 12 Dimensions
| Dimension | Deepgram Nova-3 | AssemblyAI Universal-3 | Whisper Large V3 |
|---|---|---|---|
| WER (clean audio) | ~5–6% | ~4.5–5% (lowest) | ~6–8% |
| WER (phone/noisy) | ~10–12% | ~10–11% | ~12–18% |
| Streaming latency (P50) | ~250ms (Flux) | ~150ms | 1–5s (self-hosted) |
| Native turn detection | Yes (Flux) | Partial | No |
| Hallucination rate | Medium | Lowest (30% below Whisper) | Highest |
| Language support | 30+ (Nova-3) | 99+ (Universal-3) | 99+ (pretrained) |
| Streaming price | $0.0077/min | $0.0075/min ($0.45/hr) | Free (compute cost) |
| On-prem deployment | Enterprise tier | Contact sales | Yes (self-host) |
| HIPAA BAA | Yes (Nova-3 Medical) | Yes (SOC 2 Type 2) | N/A (self-hosted) |
| PCI-DSS support | Yes | Yes | Depends on infra |
| Domain adaptation | Nova-3 Medical, custom vocab | Custom vocab boost | Fine-tuning (needs ML team) |
| Best-fit voice agent | High-volume phone, sub-800ms TTFA | Accuracy-critical + audio intel | Budget/on-prem/multi-lang + ML team |
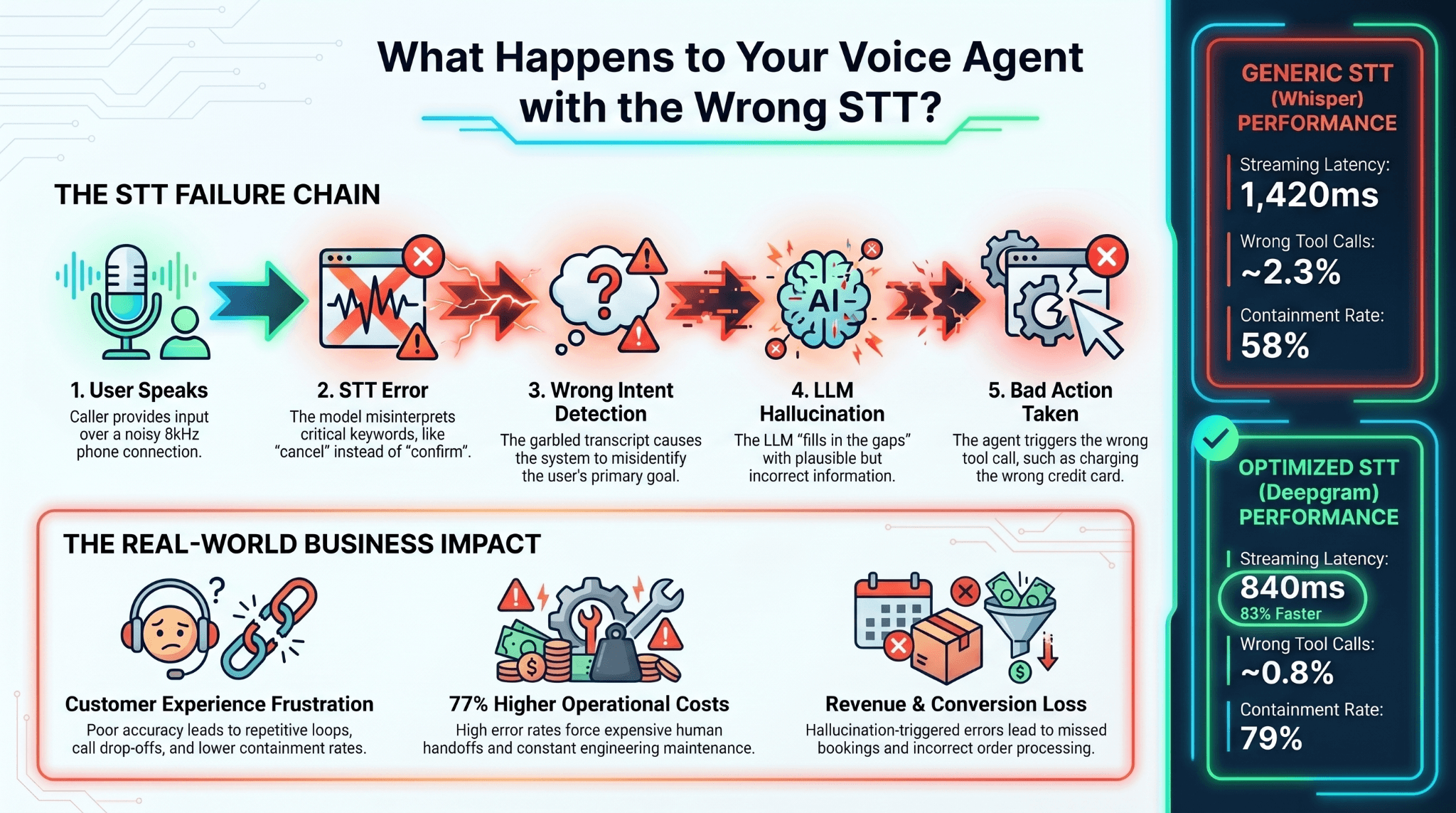
Case Study: Voice AI Startup Migrates Whisper → Deepgram
A Series A voice AI startup building healthcare scheduling agents migrated from self-hosted Whisper to Deepgram Nova-3 + Flux in February 2026 after hitting latency ceilings. Before and after metrics across the first 60 days post-migration:
| Metric | Whisper self-hosted | Deepgram Nova-3 + Flux | Change |
|---|---|---|---|
| P50 streaming latency | 1,420ms | 240ms | 83% faster |
| P95 streaming latency | 3,800ms | 410ms | 89% faster |
| Containment rate | 58% | 79% | +21 points |
| Hallucination-triggered wrong tool calls | ~2.3% | ~0.8% | 65% reduction |
| Monthly infra + eng cost | $12K compute + $8K eng ops | $4.6K API + $0 ops | 77% cost reduction |
| Engineering FTE freed | — | 1.0 FTE (from Whisper maintenance) | Back to product work |
The migration took 11 days. The team had abstracted the STT layer cleanly from day one — that abstraction paid for itself in one migration. The Whisper self-hosting had cost them 6 months of real engineering time before they realized it wasn't going to hit voice-agent latency targets.
ROI Math — 3 STT Scenarios
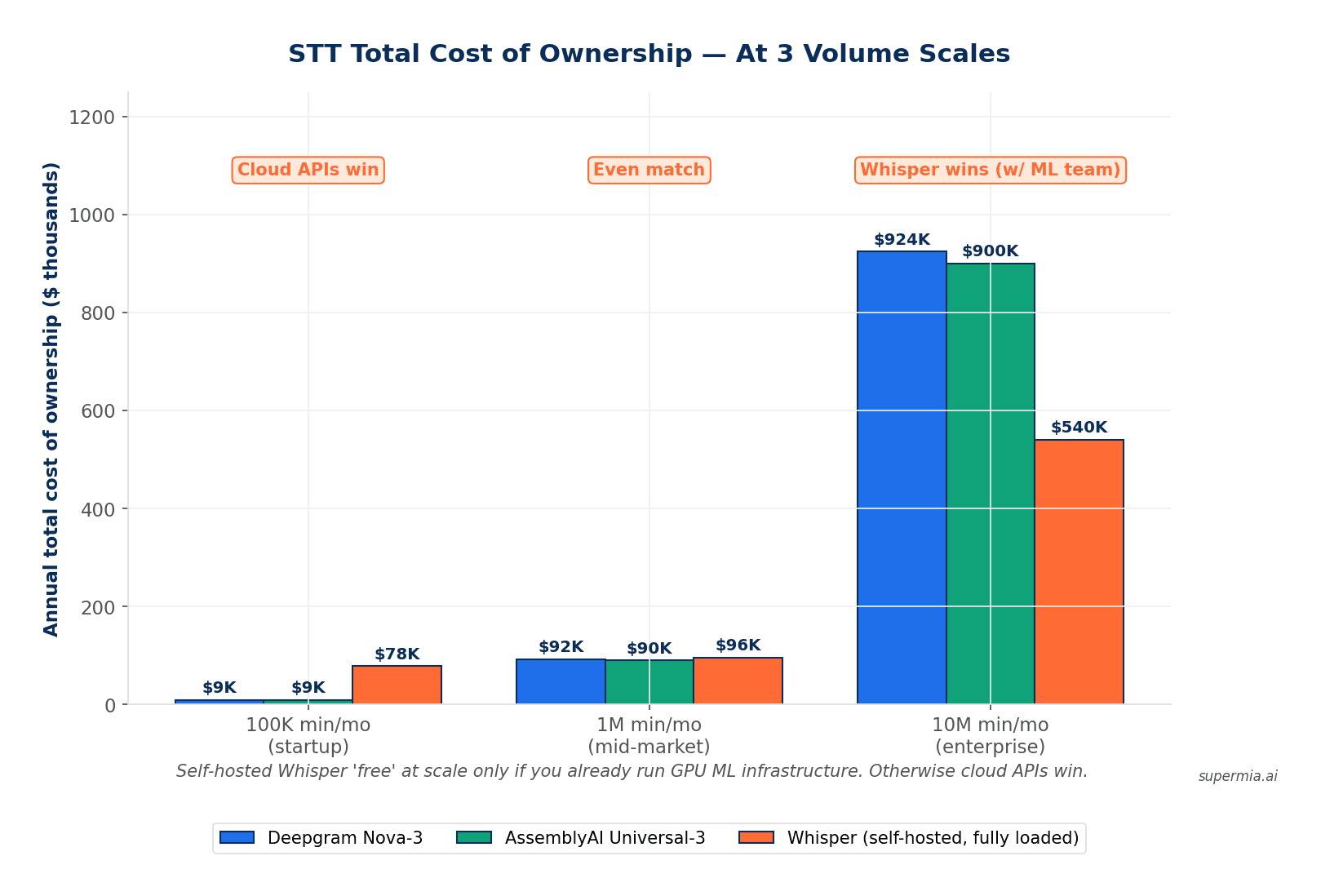
Scenario A — Startup (100K minutes/month)
- Deepgram Nova-3: $770/mo ($9.2K/yr)
- AssemblyAI Universal-3 Pro: $750/mo ($9K/yr)
- Whisper self-hosted: ~$400–1,200/mo compute + 0.5 FTE ops ≈ $5K–7K/mo fully loaded
- Winner: Deepgram or AssemblyAI. Cloud APIs beat self-hosted Whisper at this scale every time.
Scenario B — Mid-Market (1,000,000 minutes/month)
- Deepgram Nova-3: $7,700/mo ($92K/yr) — volume discounts often take this to $5.5–6.2K/mo
- AssemblyAI Universal-3 Pro: $7,500/mo ($90K/yr) — volume discounts to $5–6.5K/mo
- Whisper self-hosted (optimized): $4K–12K/mo — engineering overhead real and ongoing
- Winner: Depends on engineering capacity. Cloud APIs win on TCO unless you already run ML infra well.
Scenario C — Enterprise (10,000,000 minutes/month)
- Deepgram Nova-3: $77K/mo ($924K/yr) — enterprise contracts typically 30–40% off list
- AssemblyAI Universal-3 Pro: $75K/mo ($900K/yr)
- Whisper self-hosted with dedicated ML team: ~$35–55K/mo fully loaded
- Winner: Whisper self-hosted if you have the ML engineering capacity. Cloud APIs otherwise.
Common Objections — Honest Answers
"Benchmarks say Whisper is most accurate. Why wouldn't we just use that?"
Whisper is accurate on clean audio. Voice agents don't get clean audio — they get phone audio with background noise, overlapping speakers, and compressed codecs. On phone audio, Deepgram and AssemblyAI usually match or beat Whisper. Plus latency: Whisper's 1–5 second latency fails voice-agent requirements unless you invest heavily in inference optimization.
"Hallucination rate isn't a big deal. LLMs handle errors fine."
For text chat, sure. For voice agents with function-calling, hallucinations cascade into wrong tool calls. A hallucinated 'cancel' vs 'confirm' cancels a real appointment. A hallucinated dollar amount charges the wrong card. Plausible-sounding hallucinations are worse than obvious transcription errors because the LLM can't detect them.
"We can switch providers later. Just pick the cheapest."
You can switch — if you abstract the STT layer cleanly from day one. Most teams don't. They hard-code provider-specific confidence score handling, turn-detection logic, and custom vocabulary formats. Migration becomes a 2-month project instead of 2 weeks. Build the abstraction now if you want the option to switch later.
"We'll just run all three in parallel and pick the best output."
Expensive and complex. Parallel STT pipelines add 2-3x cost and introduce fusion logic that itself becomes a failure point. Better pattern: pick one primary based on your use case, set up a simple fallback (usually self-hosted Whisper) for provider outages, and evaluate quarterly whether your primary choice still fits.
What SuperMIA Uses — and Why
SuperMIA's production voice agent platform uses a hybrid STT architecture:
- Deepgram Nova-3 + Flux for turn detection — primary streaming STT for latency-critical phone agents
- AssemblyAI Universal-3 Pro where caller sentiment analysis and PII detection happen inline
- Self-hosted Whisper Large V3 Turbo for healthcare customers with strict on-prem requirements
The platform abstracts the STT layer, so customers can switch providers based on compliance, language, or cost without rewriting conversation logic. For the broader voice agent tech stack breakdown (STT + LLM + TTS + telephony), see our 2026 AI Voice Agent Platform Guide.
See SuperMIA pricing tiers to find the plan that matches your volume. For the pre-production evaluation framework, see our voice agent evaluation guide.
Frequently Asked Questions
The Bottom Line
Picking STT for a voice agent isn't about benchmark WER. It's about latency (sub-800ms TTFA), hallucination rate (impacts tool calls), and cost at your specific volume. Deepgram Nova-3 + Flux is the current default for phone-based voice agents. AssemblyAI Universal-3 Pro wins when accuracy or audio intelligence features matter most. Whisper Large V3 Turbo belongs in your stack when you have ML engineering capacity and specific constraints. Whatever you pick, benchmark on your own audio first.
Skip the STT decision and the 2-week evaluation entirely.
See how SuperMIA's voice agent platform handles the full stack — STT, LLM, TTS, telephony.
Book a 15-minute demo →
Harikrishna Patel
Harikrishna Patel is the founder of MIA – My Intelligent Assistant, the AI automation platform built under Botfinity Inc. in Dallas, Texas. With 15+ years in software engineering, AI/ML, and enterprise solution design, he focuses on creating practical, scalable AI tools that help businesses automate support, workflows, and operations through voice and chat.